Monday, August 10, 2020
Democratise your Data Lake with FastAPI and Cassandra
Motivation
A data platform can be thought of as a scalable system for ingestion, curation, transformation and integration of datasets. But the value of a data platform is realised when these datasets are made available for use outside the platform to drive decisions and shape the customer experience, i.e. by democratising the data.
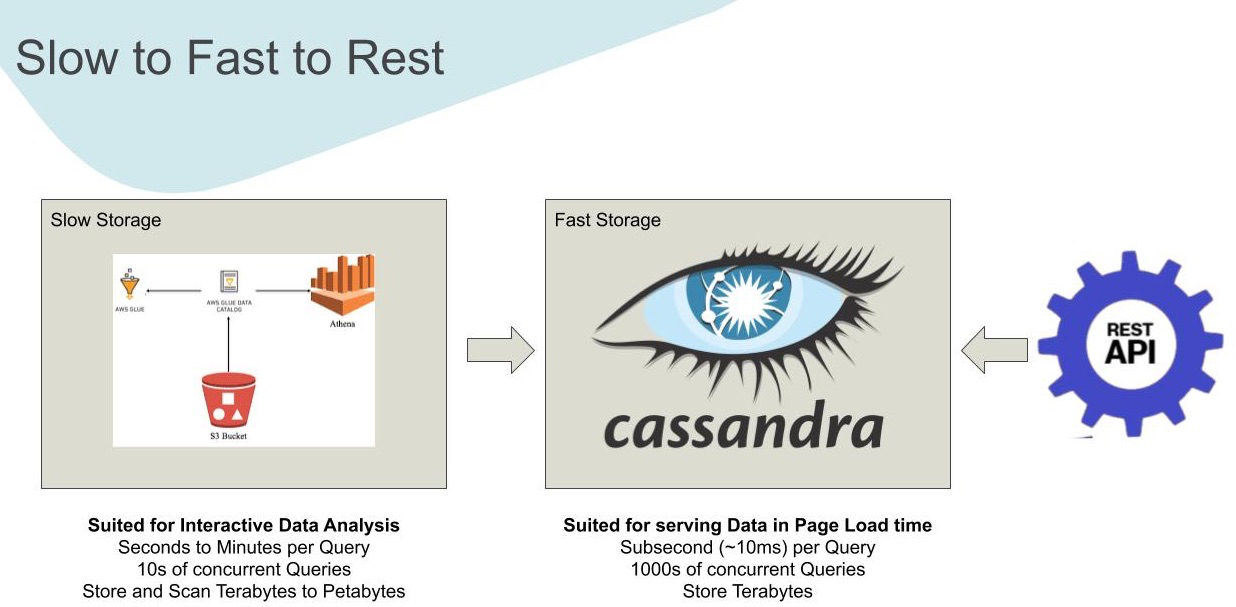
Data Democratisation may come in many shapes and sizes, with efforts typically starting with a Data Warehouse exposed via a BI framework (e.g. Looker, Tableau, Microsoft Excel..) for internal customers and employees. Eventual evolution of a data warehouse into a data lake provides a more programmatic way to access data, for data analysis, by introducing SQL interfaces, like Redshift and Athena.
At this point the data lake becomes the primary source of data for the data specialists, who transform, integrate and discover valuable insights from this data. However, this mode of access is suitable for a very specialised subset of use-cases, i.e. analytical data is usually consumed at scale, eg. years of data at a time (huge read size), but is usually not required frequently (high latency), while the consumers of such data are themselves few in number (low concurrency). Thus a system suited for analytics and reporting will have tools and platform reflecting those requirements.

As the data platform continuously improves the quantity and quality of its data assets, it is inevitable that the demand for these datasets will gain momentum especially with respect to programmatic access and integration into various applications and products.
This requires us to rethink how we make our data available for programmatic and large scale access. Requirements for integration are fundamentally different from the analytical requirements, i.e. they need very frequent access (low latency), but the scale of data returned might be relatively small (smaller read size), while the number of people or processes accessing the data can be very large (high concurrency).
Example use-case —A Generic Metric Estimator
Imagine a generic metric estimator as a reporting tool that provides an estimate based on historical data, and scanning such granular data can be time consuming, and may bump up page load times.
An obvious solution is to pre-compute the data set for every combination of possible filters which can be Million to Billions of rows. Our data pipeline does this efficiently every day and stores the result on the data lake using scalable compute (a story for another time). However, this data and subsequent dashboards were initially powered by AWS Athena, which is not suited for low latency, high concurrency queries.
As a solution, we sync our datasets from AWS Athena to Apache Cassandra using our scalable and configurable data pipeline based on Apache Airflow that syncs the results every day just after they are pre-computed.
Once we have the data in Cassandra, which supports high throughput on both reads and writes, we provide a REST interface: a Data API. We can easily integrate such an API within the product or internal BI and make it available to users from sales and service within the tools they use and are already familiar with.
Requirements
High Concurrency
We have use-cases where tens of users from our internal staff need to access data and insights about our customers, firing 100s of queries concurrently. We have use-cases for making personal scores and analytics available in our apps for hundreds of end users that need to sustain hundreds to thousands of concurrent queries.
Low Latency
Once data points are integrated into the product, they will need to match page load times, to be usable, we are talking about sub 50ms latencies for ideal user experience.
Smaller Read Size
Dashboards used by internal users rarely need to analyse across the complete population of our customers in under a second. For such use-cases, we run analytical queries that are acceptable to respond in seconds and even minutes.
Most of the datasets accessed by the product will be limited to just a few aggregated data points or at most the data for a single customer.
Scalable Datasets
While such datasets are generally consumed in small chunks, the volume of the complete data set can be quite big. Usually, the transformation and curation of these datasets are done at scale spans 100s of Millions to Billions of rows, while the data consumed at any one point is in order of 10 to 100 rows.
High Write Volume
Currently, we use batch data pipelines to stage our data onto Cassandra, which means high volume at write time, while we need to be future proof, and be ready for low latency ingests from streaming sources like click-stream and domain events, so a very high volume low latency data store is warranted.
Solution Design
Focusing on the above problem statements, we recently deployed a scalable data store using Apache Cassandra, which serves as the foundation for our datasets. In order enable programmatic access to the data stored in Cassandra, we needed a scalable and easy to access pass-through layer, an API layer or Data API.
Expose Datasets not Domain Objects
The Data API aims at exposing analytical datasets, rather than domain objects and their state, i.e. we will not be exposing any transactional data, that is the realm of the application. For use-cases that require handling states and being aware of domains of the business, we recommend using the application platform as they will always be a source closer to the truth.
This platform is meant for exposing scalable analytics and aggregated or transformed data to external systems. The business logic and transformation, in this case, is the responsibility of upstream data pipelines. For fast access, we need to make sure the data is pre-computed and ready to be consumed.
The Data API is a pass-through wrapper that provides an abstraction to Apache Cassandra, so external systems do not need to deal with low-level Cassandra drivers and its Query Language CQL. Hence we define no business logic in the Data API layer.
Data Latency is different from Read Latency
This solution is dealing with the read latency, i.e. optimise for stored data to be presented in sub-second latencies, which is different from the data latency which is time elapsed between the creation or inception of a given data point to the time it lands in user’s hands.
This is why the Data API is only suitable for exposing analytical datasets, for use-cases that are tolerant of some data latency.
Most of the said data latency is related to pre-processing of data that happens upstream to Cassandra, and we can minimise it by moving our transformation from batch to stream, however, it might not always be possible to do that, and considering data latency for choosing a use-case is important.
Minimal code for new DataSets
We are a young and growing data platform, and we expect to see an explosion in the datasets we produce. We need to make it extremely easy to quickly serve an existing dataset in the form of an API. Much of the work related to standing up the infrastructure for each data set is repeated and thus we automated — the lot. The service auto-discovers and exposes existing datasets as REST Endpoints.
Data Discoverability
Our platform is seeing a quick rise in the datasets that are available as API. We need an easy way for the consumers of this API to discover and capitalise on the new goodies that are made available on a regular basis. Thus we exposed metadata through the same API:
- List available datasets
- Indicate data staleness
- List available fields
- List available versions
- Interactive API documentation
- REST with FastAPI
FastAPI is a popular Python framework for writing efficient APIs. This project has become my personal favourite recently, because of the clean API approach, flexibility, out of the box interactive Swagger docs, along with beautiful redoc presentation. On top of that, it works with model and metadata configuration using Pydantic, which makes it an obvious choice.
Most external systems understand REST and we are likely to encounter systems in the future that require a REST endpoint for integration.
GraphQL is a flexible query language for the API, but most of the GraphQL advantages that stem from the relationships between entities. Our datasets endpoints exclusively expose a single entity (dataset), and there are no relationships between these entities, making this API a poor candidate for implementing GraphQL. Hence we stick with simple REST endpoints.
Version Control
Datasets evolve over time, change in the data itself does not trigger any version change on the API, but a change in the available fields and the data types will need to be handled via data set versioning.
We manage the version during the creation of datasets, and thus every change in the schema of the dataset should result in an automatic version bump, thus also generating a new API endpoint.
This type of tight coupling means we will not need to deal with increasingly complex versions like DatasetA_v_1__API_v_2 rather we can decipher the version from the dataset name and pass that on to the API, so DataSetA_v_1 relates to API_A_v_1.
JSON API Spec
The JSON API spec is a data format standard that relies on JSON serialisation, and defines certain fields and structure to the data being passed to and from an API. We have adopted the JSON API spec as a standard, as it is widely used in other engineering teams, and makes it easier to reason about field names and structures present in the results.
Data Flow
Data Flow Architcture of the Data API

What’s Next
We plan on exposing more of our Data Lake to internal and external customers and applications. As adoption grows, we will likely see feature requests and enhancements to the Data API platform. In near term, we plan on extracting the core components of this platform and open-sourcing it. Stay tuned for more news on that. Thanks to Fabian Buske and Christopher Coulson.