Friday, September 1, 2023
Harnessing Lineage for Continuous Improvement in your Deep Learning Datasets
In the world of deep learning, the foundation of model success rests upon the datasets they are trained on. These datasets act as the lifeblood of machine learning applications for solving real world problems. While both supervised and unsupervised datasets play crucial role in shaping the capabilities of deep learning models, it’s the supervised datasets that stand out as the gold standard for achieving robust and reliable performance. These datasets come armed with meticulously and usually human labelled ground truth, guiding the models towards precision.
However, the journey to model excellence doesn’t end at dataset creation. Just as a sculptor refines their masterpiece over time, the process of continuous improvement in deep learning datasets is equally vital. This blog will delve into the significance of continuously improving datasets, specifically improving the quality of labels rather than quantity.
As you may have inferred, improving quality of existing labels clearly means corrections and improvement on labels that may have originated some time ago from another model, model assisted human labels or pure ground truth labels from a human. and as such may or may not have been used to train previous generations of models. Maintaining the older “versions” of these labels is crucial for reproducibility and tracking.
Traditionally open datasets have solved these problems by just publishing newer versions of the entire dataset as newer copies, while maintaining older copies for future access. This works well for relatively sow moving datasets that donot need to maintain any references to their older data points. COCO is an example of this approach, where newer versions available to download independently.

For industrail scale real world machine learning, where we need to gather 10s of millions of images with 100s of millions of labels which are improved continuously, where we are training new models every month if not every week with industrial scale reproducibility and tracking, many times for governance and compliance purposes, this solution does not scale very well.
This is where a Lineage tracking becomes inevitable, allowing large scale datasets to evolve at speed and scale while not compromising on tracking, reproducibility and flexibility.
What is Lineage?
Lineage refers to the historical record of the origin, transformation, and evolution of data. It encompasses the entire lifecycle of data, including its creation, processing, and any changes it undergoes over time.
In the context of this text I will use the word lineage to describe the transformation or correction of ground truth over time as humans, assisted with different tools and knowledge identify and fix mistakes in extisitng ground truth.
An example of what this may look like in practice:
Imagine the case of semantic segmentation of buildings on aerial imagery. We select a region on the map, and send it to be labelled with an expert human labeller:

While the human labelled the image to the bst of their knowledge, they may have missed a spot. This can happen and for this reason, you have quality control, model validation and various other methods in place, so that another human can verify and fix the label as you find issues with it.

While this seems simple enough, the time between the original label and the correction of label can span over months and years, meanwhile we may have already trained and deployed our deep learning models and can’t afford to lose the information about the original label and the new one.


A DAG emerges
As you can imagine tracking lineage like this will result in a Directed Acyclic Graph (DAG) of annotations, that sit within the larger graph of feature and label dataset. Capturing this information with your annotations is only part of the challenge, what you really need is a way to transform this into a training dataset.
This can pose a graph traversal and consolidation challenge, as you may have may have many possible structures.


A naive approach can be to aggregate all the labels ever gathered together.

This approach makes some sense, as you are building consensus from many human labels, but in reality, we are ignoring the fact that new information, improvement in tooling, knowledge and expertise has resulted in better labels, thus aggregating with older labels dilutes and in some cases reverses the quality gained by these improvements.
A less wasteful approach is to boost the data that has passed through more human attention, and we can do that easily by figuring out the leafs of these DAGs and discard the parent nodes.
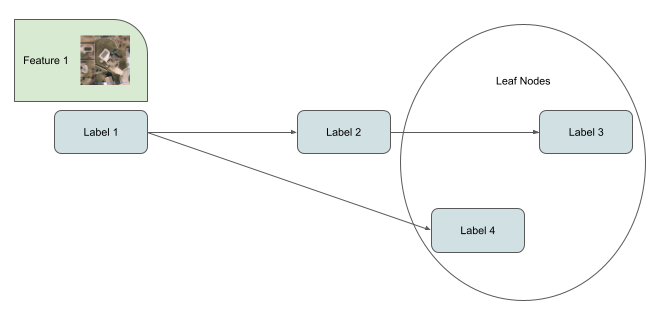
This approach guarantees that there will alleyways be an improvement with ever correction in your dataset. However you may sill end up with many leaf nodes, and you can use different strategies to tackle that based on the problem at hand, a couple of example solutions that that can be considered:
Human in the loop consolidation of two labels into one.
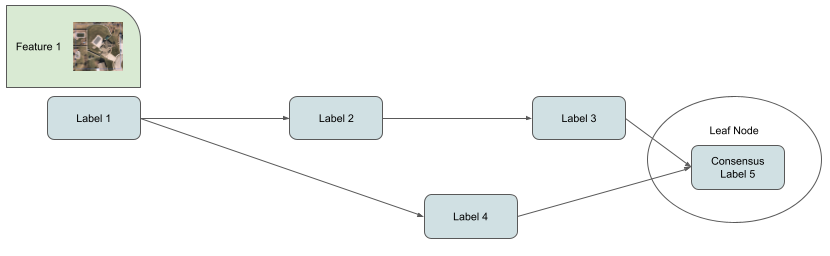
Or simple aggregation of leaf nodes.
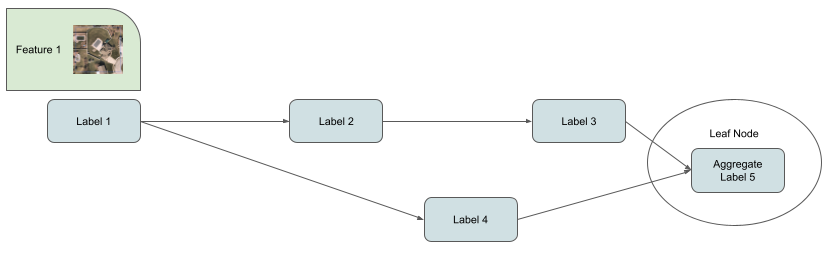
These approaches finally reset in what the model is trained on, a feature + label pair.
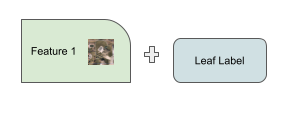
But a singular feature label pair does not a dataset make. We need a dataset where millions of such DAG traversals and consolidations need to be computed to freeze a trainable dataset.
Tackling Lineage at scale
How do we tackle such tree traversals in a way that it scales while still maintaining reliability and transparency? This is where managing metadata in scalable query engines can come in handy. SQL engines are traditionally excellent at handling tree and graph structures, They are battle hardned and workreallywell with arbitary relational data, and computing such relationships on the flay.
Consider modern data warehouses such as AWS Athena, Snowflake, Google BigQuery, even a simple postgres database would suffice for the following solution.
Serialise a graph of metadata onto a table with parent relationships. Having immutable data is quite important for maintaining integrity and reproducibility over time, and thus only the children record their paren relationships as new children are introduced, and the table grows linearly.
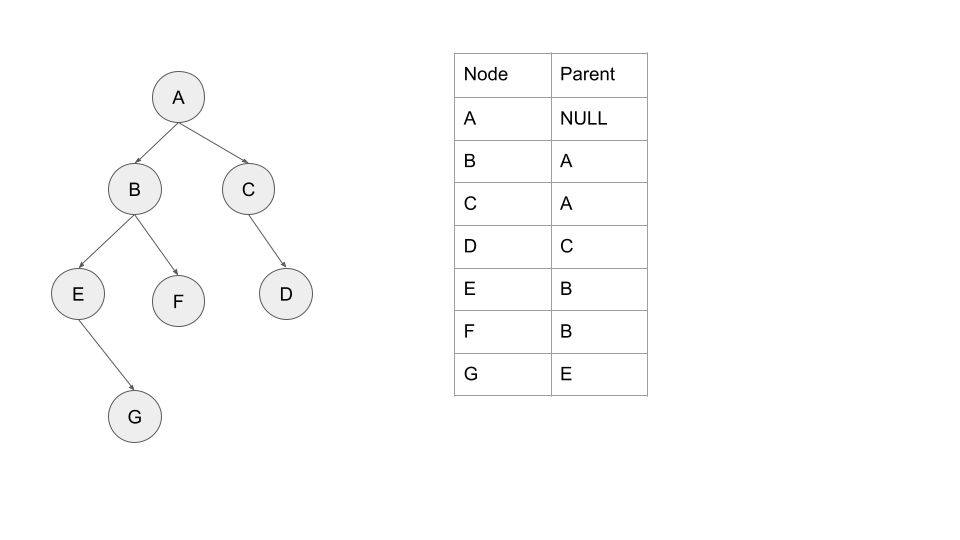
Using simle SQL semantics, we can traverse and calculate parents for each node.